About this article:
This short article describes how to author an ontology with semAuth.
The article has the logical media type "print article", thus it is designed to be read (as opposed to be presented).
It contains a significant amount of text. This text is meant to be a surrogate for explanatory text, which is typically given in a slide based conference presentation.
Find a conference style representation - i .e. annotated slides - of the identical content at
 pdk1slides
.
pdk1slides
.
Expressing facts
Be the domain of our example the field of persons who are authors of texts which are in turn on a specific topic.
Our specific sand box use case then is on finding experts on given subjects and maintaining a taxonomy of subjects. An "expert" is an author who has written a book on a given subject.
Be the modelling task to craft an ontology which is on persons (and authors), documents and related keywords.
Representing PDK in a mindmap
In our sand box use case an end user - say Erica - crafts a shallow outline of the ontology using a standard mindmapping tool.
She probably will end up with a map like the following:

semAuth translates this map into the following nested list:
-
Person
- Author Stanislav_Lem (other spelling: Stanisław Lem) isAuthorOf The_Cyberiad
- Isaac_Asimov (other spellings: Исаак Озимов or Айзек Азимов ) isAuthorOf I_Robot
- Tobias Findeisen
-
Document
- Book
-
Story
- The_Cyberiad hasKeyword robot
- I_Robot hasKeyword human robot
-
artefact
-
machine
- vehicle
-
robot
- human robot
-
machine
Annotating the mindmap with semantic icons
We further assume that our end user Erica a highly qulified scientist, who has shallow knowledge about the semantic web. She has heared about RDF and believes to know that there are classes and instances, data and object properties, subject and object resources and data literals. While Erica's terminology is not totally correct (and influenced by unclear ideas about OWL), it is a good starting point for communicatingwith an experienced ontology engineer in subsequent phases of her ontology egineering project.
After a short introduction into the semAuth semantic tagging grammar
Erica applies her knowledge to her outlined ontology.
The result looks like the following map:
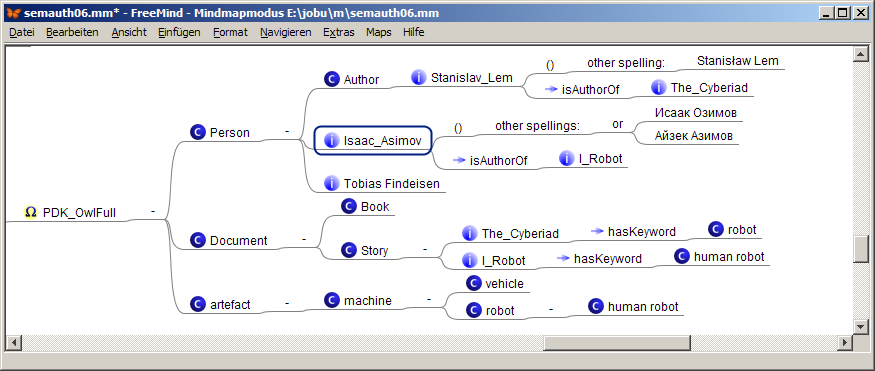
html export of PDK_OwlFull
The script semAuth.xsl exports this map snippet into the following html snippet:
-
 PDK_OwlFull
PDK_OwlFull
-
 Person
Person
-
Author
Stanislav_Lem
(other spelling:
Stanisław Lem)
 isAuthorOf
The_Cyberiad
isAuthorOf
The_Cyberiad
-
Isaac_Asimov
(other spellings:
Исаак Озимов or Айзек Азимов
)
isAuthorOf
I_Robot
-
Tobias Findeisen
-
-
Document
-
artefact
-
Refacturing the OWL full ontology to OWL DLP
Looking at Erica's modelling Olivia, an experienced ontology engineer, recognizes several problems.
- Erica's model is perfectly fine in pure RDF; however, if the ontology is meant to load into a reasoner it sometimes becomes a problem that the complexity of the ontology is equivalent to OWL full. (In fact Erica utilized a problem solution which is broadly discussed under the title "Representing Classes As Property Values on the Semantic Web", c.f. http://www.w3.org/TR/swbp-classes-as-values )
- Additionally Erica in fact provides not much more than a fact box plus a trivial taxonomy of artefacts. The model given lacks information which could be exploited for more sophisticated inferencing services like classification or integrity checks.
Erica asks Olivia to improve her modelling; it results the following map:
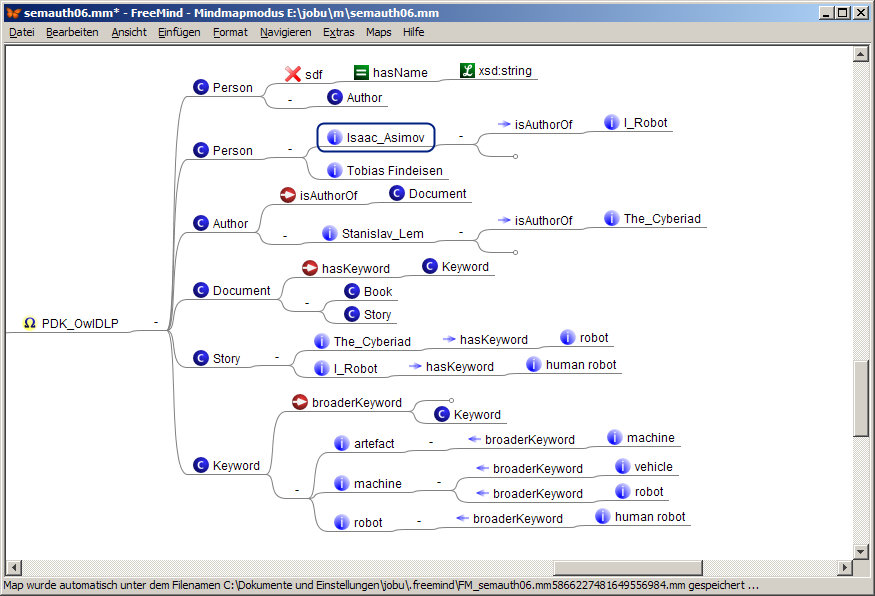
The script semAuth.xsl exports this map snippet into the following html snippet:
-
PDK_OwlDLP

Olivia's improved version now is a good first approach to represent the desired domain. The most important change w.r.t. Erica's model is that the taxonomy of artifacts was refactured as a tree of instances of the (additionally introduced) class Keyword. (An ontology engineering expert here recognizes that we have reformulated the SKOS modelling pattern in own words., This was for didactical reasons only., In a real ontology project we of course would make use of the original SKOS ontology.)
Adding (and interpreting) schema information
Another notably refinement is that
Olivia added some schema information to the ontology, i.e.
PDK_Schema1
-
Person
 hasName
hasName
 [xsd:string]
[xsd:string]
-
Author
 isAuthorOf
Document
isAuthorOf
Document
-
Document
hasKeyword
Keyword
-
Keyword
broaderKeyword
Keyword
While adding schema information like domain and range statements to an ontology is in fact is a core of professional ontology engineering, it opens two serious questions:
- What does an end user want to express which such an information?
- What does an inferencing engine derive from such an information?
The answer significantly depends on the ontology language you use for implementing an ontology.
In RDFS and OWL the domain and range information given is used for *deriving* the type of the subject and the object of a S P O triple.
An RDFS inferencing engine will derive that Isaac_Asimov is an Author, because is the subject of the triple
Isaac_Asimov
isAuthorOf
I_Robot
. (Have you noticed that Asimov is declared to ba an instance merely of the class Person instead of the class Author?)
The same engine also will classify
robot
being a keyword because of the same reasons.
This kind of inferencing is known as
type entailment
and well defined in the semantics of RDFS
(c.f. rule
rdfs3
in
http://www.w3.org/TR/rdf-mt/#RDFSRules
).
In F-Logic the domain and range information is interpreted being an integrity constraint by default.
In our example the inferencing engine would complain that the relation
isAuthorOf
is not defined for the subject
Isaac_Asimov
.
-- And yes:
In case somebody would like to simulate the RDFS type entailment semantics this can be done withfew trivial F-logic rules.
In our example a specific type entailment rule for the relation
broaderKeyword
probably would be appropriate.
The semAuth mindmap representation plus a F-Logic translation looks like:
|
@{
AllKeywords
}
?-
@{
KeywordTypeEntailment
}
|


While ontology engineering workbenches like Protégé or OntoStudio are frontends to specific ontology languages like OWL or F-logic,
semAuth provides a tagging syntax which is only loosely coupled with a specific language.
A schema statement like
Author
isAuthorOf
Document
can be translated into several languages and thus express different semantics.
Even more: If exporting to a F-logic representation semauth allows you to express in a declarative way which property type definitions should be interpreted (i.e. simulated by rules) as RDFS type entailments or as integrity constrains.
To our experience this is a feature which is well acknowledged by end users who develop conceptualizations step by step in order to clarify their own understandings of a domain.
Our example shows that the semAuth grammar clearly is lacking a specific semantic. Instead the semantic of a semAuth map is dependent on the semantics of the exported ontology language and the translation of self defined icon annotations as a shortcut for certain rules. We consider this beeing not a bug but a feature of our approach, because it allows for a step by step transition from very informal to specific formal and well defined representations.
Adding explicit rules
The only thing which is left to be done is to make implicit knowledge explicit, here: to derive who is expert on a given subject.
An according semAuth representation and F-Logic translation would look like: Somebody who has written a document on a subject is an expert on this subject:
|
@{
WhoIsExpertOnSubject
}
?-
@{
expertOnSubjectRule
}
|
Until now the rule doesn't exploit the hierarchy of keywords (as it would have been the case if we would have modelled it with a class hierarchy as initially done by Erica.) The following rule compensates this shortcoming: Somebody who is an expert on a concept Y which has a broader concept Z is also an expert on Z:
|
@{
SubjectToBroaderSubject
}
?-
@{
TransitivRule
}
|
That's all: We now have a nice rule based ontology which allows for asking for experts on a given subject -- based on a subject tree.
Graphical representation of the ontology
The tool semAuth automatically generates a graphml representation of each module within a semantically tagged mindmap. In order to enhance the technical modularity of the approach semAuth itself does not apply any layout to the graph, it only allocates nodes and edges. In order to get a properly layouted graph you have to load the exported graph into an appropriate graph layout tool. We make use of the free yEd editor from http://www.yworks.com .
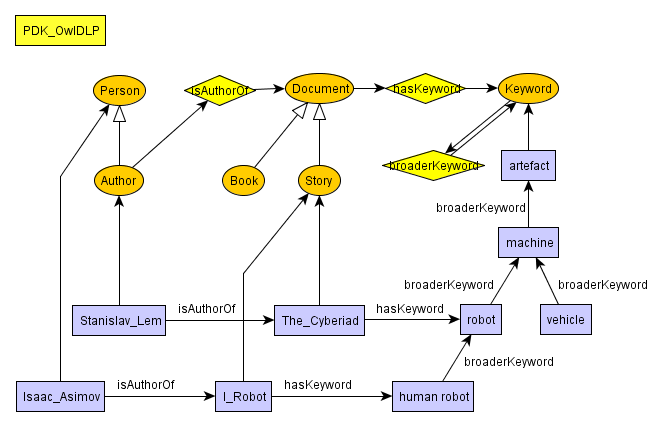
The image above contains only the nodes and edges created by semAuth automatically. However, the elements where arranged manually.