Korpus einlesen#
gegeben: eine oder mehrere Chats, wie sie von duck.ai exportiert werden.
gesucht: eine Datenstruktur, die uns die Chat-Inhalte gut zugänlich aufdröselt.
import pathlib
import re
import pandas as pd
global_verbose = 2 # 0: keine Info-Ausgabe; 1: minimale informative Info-Ausgabe; 2: ganz viel Debug-Ouptut
default_ngram = 3
usertag = [ 'Benutzereingabe', 'Підказка користувача' ]
models = [ 'Claude Haiku 3.5', 'GPT-4o mini', 'GPT-5 mini',
'GPT-OSS 120B', 'Llama 4 Scout', 'Mistral Small 3' ]
# alle Elemente aus usertag in eine regex umbauen:
# 'Benutzereingabe' ODER 'Підказка користувача' ODER ...
regex_usertag = '|'.join(fr'\s+{tag}\s+' for tag in usertag)
# print(f"DEBUG {regex=}")
# aus der Liste der bekannten Modelle eine regex bauen:
# Claude Haiku 3.5' ODER 'GPT-4o mini' ODER 'GPT-5 mini' ODER ...
# (die verfügbaren Modelle müssen dazu bekannt sein)
regex_models = '|'.join(fr'\s+{tag}:\n' for tag in models)
# print(f"DEBUG {regex2=}")
class Chat():
def __init__(self, path, *, verbose = global_verbose):
self.path = pathlib.Path(path)
if verbose >=2 : print(f"INFO 11: reading {str(self.path)}", end = "")
with open(self.path,
"r", # default
encoding="utf-8-sig" # remove Byte Order Mark (BOM) if necessary
) as p:
self.fulltext = p.read()
if verbose >= 2: print(f"... got {len(self.fulltext)} bytes")
# fulltext in einzelne Frage-Antwort-Interaktionen aufsplitten
self.interactions = re.split(regex_usertag, self.fulltext)
# duck.ai generiert einen (leidlich uninteressanten) Kopf, der mit "======" endet.
self.head = self.interactions.pop(0)
# body: Darstellung des Chats als Tabelle
# Jede Interaktion ist eine Zeile in der Tabelle
# Implementierung wie bei https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.from_dict.html
# * initial mit den Spalten prompt, answer
# * leicht erweiterbar durch zusätzliche Spalten wie clean, n-grams etc.
self.body = { "timestamp": [], "prompt": [], "answer": [] }
# für jede Interaktion
for i in self.interactions:
timestamp, text = i.split(':\n', 1) # erste Zeile ist timestamp
self.body["timestamp"].append(timestamp)
# Aufsplitten in Promt, Answer
splt = re.split(regex_models, text, maxsplit=1)
self.body["prompt"].append(splt[0])
self.body["answer"].append(splt[1])
# Pandas DataFrame generieren
self.update_df_from_body()
def update_df_from_body(self):
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.from_dict.html
self.df = pd.DataFrame.from_dict( self.body )
def update_body_from_df(self):
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_dict.html
self.body = self.df.to_dict(orient='list')
Welche Dateien haben wir?
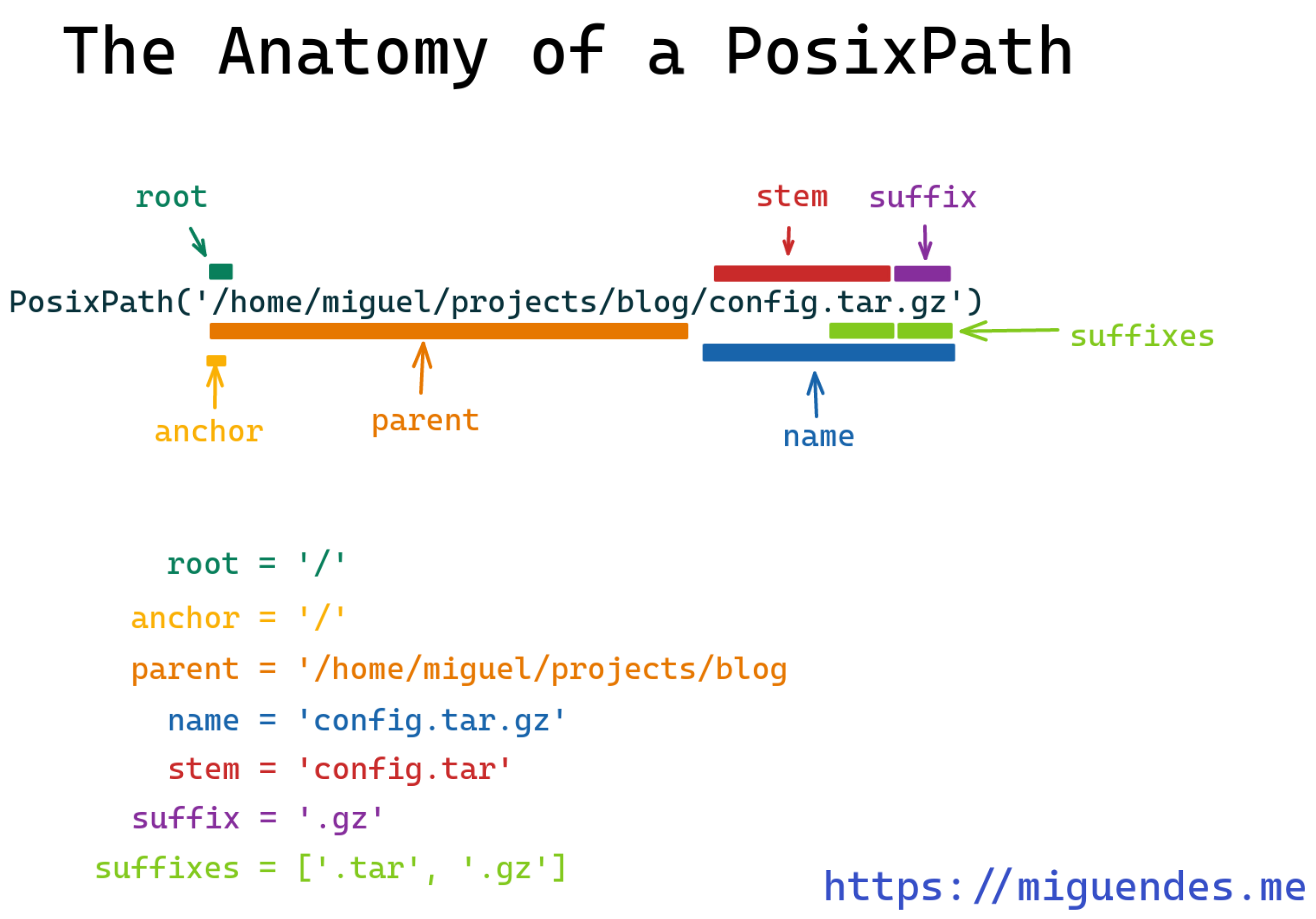
Begriffliche Grundlagen “Datei”, “Pfad” etc.: https://miguendes.me/python-pathlib#the-anatomy-of-a-pathlibpath, gute Abbildung: https://cdn.hashnode.com/res/hashnode/image/upload/v1635494392030/uomUWH2vC.png
{kind=link}
import glob
corpus_folder = "../korpus_2025-10-17/"
corpus_glob_pattern = corpus_folder + "**/*"
files_path = glob.glob( corpus_glob_pattern )
if global_verbose >= 1:
print(f"INFO 19: {corpus_glob_pattern=} found {len(files_path)} files")
len(files_path), files_path[0:3]
INFO 19: corpus_glob_pattern='../korpus_2025-10-17/**/*' found 33 files
Für jede Datei aus files_path eine Instanz der Klasse Chats anlegen, in der dann alle Infos zusammengefasst sind.
chats = { str(path): Chat(path, verbose=0) for path in files_path }
Kontrolle: Welche Chats haben wir z.B. von claude?
[ c for c in chats.keys() if '/claude' in c ]
['../korpus_2025-10-17/claude-haiku-3.5/duck.ai_2025-10-17_10-48-19-claude.txt',
'../korpus_2025-10-17/claude-haiku-3.5/duck.ai_2025-10-17_10-50-29_regex_Claude_Haiku_3_5.txt',
'../korpus_2025-10-17/claude-haiku-3.5/duck.ai_2025-10-17_10-51-26_Haiku35.txt',
'../korpus_2025-10-17/claude-haiku-3.5/duck.ai_2025-10-17_10-48-24_claude-haiku.txt',
'../korpus_2025-10-17/claude-haiku-3.5/duck.ai_2025-10-17_10-50-24_regex_Korpus_1_Claude_Haiku_3.5.txt']
Für Debug- und Demo-Zwecke wollen wir uns eine frei wählbare, dann aber feste Instanz herauspicken:
example_chat = chats["../korpus_2025-10-17/claude-haiku-3.5/duck.ai_2025-10-17_10-50-29_regex_Claude_Haiku_3_5.txt"]
Informationen auslesen#
So können wir nun auf diesen Chat zugreifen:
example_chat.path
PosixPath('../korpus_2025-10-17/claude-haiku-3.5/duck.ai_2025-10-17_10-50-29_regex_Claude_Haiku_3_5.txt')
print( example_chat.fulltext[:500] )
Ця розмова згенерована за допомогою Duck.ai (https://duck.ai) моделі Claude Haiku 3.5 Anthropic. Чати зі ШІ можуть містити неточну або образливу інформацію. (Докладніше читайте тут: https://duckduckgo.com/duckai/privacy-terms).
====================
Підказка користувача 1 з 2 - 17.10.2025, 10:49:54:
Erkläre einem Kind in der Grundschule reguläre Ausdrücke
Claude Haiku 3.5:
## Reguläre Ausdrücke für Kinder: Eine spielerische Erklärung
Stell dir vor, du hast eine magische Suchbrille, die dir hi
example_chat.body.keys()
dict_keys(['timestamp', 'prompt', 'answer'])
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.from_dict.html
example_chat.update_df_from_body()
example_chat.df
| timestamp | prompt | answer | |
|---|---|---|---|
| 0 | 1 з 2 - 17.10.2025, 10:49:54 | Erkläre einem Kind in der Grundschule reguläre... | ## Reguläre Ausdrücke für Kinder: Eine spieler... |
| 1 | 2 з 2 - 17.10.2025, 10:50:08 | Erkläre auf Hochschulniveau reguläre Ausdrücke | ## Reguläre Ausdrücke: Formale Theorie und Pra... |
So könnte man weitermachen#
Filtere aus den LLM-Antworten alle nicht alphanumerischen Zeichen heraus.
def clean(text):
"""Remove chars that are not isalnum(), condense subsequent spaces."""
def alnum(x): return x if x.isalnum() else " "
cleaned = "".join( alnum(c) for c in text)
return " ".join( [ word for word in cleaned.split() if len(word) > 1 ] )
konservative Programmierung ohne Pandas Dataframe: Wir fügen eine neue Spalte cleaned hinzu.
for chat in chats.values():
chat.body["cleaned"] = [] # We allocate a new col in the table "body" from **from outside the instance: UGLY!**
for text in chat.body["answer"]:
chat.body["cleaned"].append( clean( text) )
chat.update_df_from_body()
example_chat.df
| timestamp | prompt | answer | cleaned | |
|---|---|---|---|---|
| 0 | 1 з 2 - 17.10.2025, 10:49:54 | Erkläre einem Kind in der Grundschule reguläre... | ## Reguläre Ausdrücke für Kinder: Eine spieler... | Reguläre Ausdrücke für Kinder Eine spielerisch... |
| 1 | 2 з 2 - 17.10.2025, 10:50:08 | Erkläre auf Hochschulniveau reguläre Ausdrücke | ## Reguläre Ausdrücke: Formale Theorie und Pra... | Reguläre Ausdrücke Formale Theorie und Praktis... |
Füge auf Basis der gesäuberten Antworten die entsprechenden 3-Gramm-Sets hinzu
def n_gram_set(text, n=default_ngram):
"""return lowercase n-grams based on text"""
return { text[i:i+n].lower() for i in range(0, len(text)-n+1) }
#n_gram_set("abcdabc")
Schnelle, elegante Lösung durch vektorisierte Pandas Funktion:
for chat in chats.values():
chat.df['ngram'] = chat.df['cleaned'].apply(n_gram_set)
chat.update_body_from_df()
example_chat.df
| timestamp | prompt | answer | cleaned | ngram | |
|---|---|---|---|---|---|
| 0 | 1 з 2 - 17.10.2025, 10:49:54 | Erkläre einem Kind in der Grundschule reguläre... | ## Reguläre Ausdrücke für Kinder: Eine spieler... | Reguläre Ausdrücke für Kinder Eine spielerisch... | { in, ir , l u, ric, kuc, lär, cke, hr , sdr, ... |
| 1 | 2 з 2 - 17.10.2025, 10:50:08 | Erkläre auf Hochschulniveau reguläre Ausdrücke | ## Reguläre Ausdrücke: Formale Theorie und Pra... | Reguläre Ausdrücke Formale Theorie und Praktis... | {pha, mpi, pe, tzu, ve, n v, lun, fre, sit, ... |
e.g. jaccard similarity between two LLM answers, here interaction #0, child answer:
example_chat.fulltext[:500]
'Ця розмова згенерована за допомогою Duck.ai (https://duck.ai) моделі Claude Haiku 3.5 Anthropic. Чати зі ШІ можуть містити неточну або образливу інформацію. (Докладніше читайте тут: https://duckduckgo.com/duckai/privacy-terms).\n\n====================\n\nПідказка користувача 1 з 2 - 17.10.2025, 10:49:54:\nErkläre einem Kind in der Grundschule reguläre Ausdrücke\n\nClaude Haiku 3.5:\n## Reguläre Ausdrücke für Kinder: Eine spielerische Erklärung\n\nStell dir vor, du hast eine magische Suchbrille, die dir hi'
type( example_chat.body["ngram"][1] ) # 3gram representation of second answer (answer with index 1)
set
print( list( example_chat.body["ngram"][1] )[:20] )
['pha', 'mpi', ' pe', 'tzu', ' ve', 'n v', 'lun', 'fre', 'sit', 'esc', 'räs', 'lär', ' pa', 'cke', 'ore', 'e n', 'woh', 'hr ', 'sdr', 'zen']
example_chat_2 = chats['../korpus_2025-10-17/claude-haiku-3.5/duck.ai_2025-10-17_10-51-26_Haiku35.txt']
print( example_chat.body["cleaned"][1] )
Reguläre Ausdrücke Formale Theorie und Praktische Implementierung Theoretische Grundlagen Reguläre Ausdrücke sind eine formale Beschreibungsmethode von Zeichenketten die direkt mit der Theorie formaler Sprachen und Automatentheorie verknüpft sind Sie repräsentieren eine präzise mathematische Notation zur Beschreibung von Zeichenmustern Konzept Mathematische Definition Implementierungsaspekt Alphabet Endliche Menge von Symbolen Zeichensatz ASCII Unicode Reguläre Sprache Durch endliche Automaten erkennbar Mustererkennungsmechanismus Kompositionalität Rekursive Komposition von Teilausdrücken Verschachtelung von Regex Operatoren hr Theoretische Konstrukte Grundoperationen Konkatenation Verkettung von Teilausdrücken Vereinigung Alternative Muster Kleene Stern Beliebige Wiederholung Formale Darstellung beschreibt die Sprache eines regulären Ausdrucks Rekursive Definition durch leere Zeichenkette Einzelne Symbole Vereinigung R1 R2 Konkatenation R1 R2 Iteration Kleene Stern hr Implementierungsebene Kompilierungsprozess Regulärer Ausdruck Nichtdeterministischer Endlicher Automat NFA NFA Deterministischer Endlicher Automat DFA Minimierung des Automaten Komplexitätsanalyse Konstruktion NFA Umwandlung NFA DFA Potenzmengenkonstruktion exponentiell Mustersuche wobei Musterlänge Textlänge hr Praktische Anwendungsszenarien Domänenspezifische Validierungen Mail Adressen Telefonnummern Datumsformate Parsing und Compiler Technologie Lexikalische Analyse Tokenisierung von Quellcode Syntaktische Vorverarbeitung hr Theoretische Grenzen Chomsky Hierarchie Reguläre Ausdrücke entsprechen Typ Grammatiken Begrenzte Ausdruckskraft Können nicht kontextfreie Sprachen nicht beschreiben Beispiel Palindrome oder verschachtelte Klammerstrukturen Performanz Herausforderungen Backtracking bei komplexen Mustern Exponenzielle Laufzeit bei pathologischen Regex Konstruktionen Mechanismen zur Komplexitätsbegrenzung notwendig hr Fortgeschrittene Konzepte Lookahead und Lookbehind Capture Gruppen Nicht greedy Matching Unicode Unterstützung Die Beherrschung regulärer Ausdrücke erfordert ein tiefes Verständnis sowohl der theoretischen Grundlagen als auch der praktischen Implementierungsdetails
print( example_chat_2.body["cleaned"][1] )
Reguläre Ausdrücke Eine Tiefenanalyse für Informatiker und Softwareentwickler Theoretische Grundlagen Reguläre Ausdrücke Regex sind eine formale Beschreibungsmethode von Zeichenketten die direkt aus der Automatentheorie und formalen Sprachen stammen Sie repräsentieren eine kompakte mathematische Notation zur Beschreibung von Zeichenmustern Mathematische Fundierung Konzept Theoretische Beschreibung Formale Notation Alphabetische Grundlage Endliche Menge von Symbolen Reguläre Sprache Durch endliche Automaten erkennbare Sprache Kleene Stern Wiederholungsoperator AA AAA Theoretische Konstruktion Reguläre Ausdrücke werden rekursiv über folgende Grundoperationen definiert Basiselemente Leeres Wort Einzelne Zeichen Zeichenklassen Kompositionsoperatoren Konkatenation Verkettung Vereinigung Alternation Kleene Stern Wiederholung Implementierungsaspekte Matching Algorithmen Thompson Konstruktion Umwandlung regulärer Ausdrücke in Nicht Deterministische Endliche Automaten NEA Subset Konstruktion Determinierung des Automaten Komplexität wobei die Länge des Musters und die Länge des Texts beschreibt Fortgeschrittene Konzepte Erweiterte Regex Funktionalitäten Lookbehind und Lookahead Capture Gruppen Nicht greedy Matching Backreferences Praktische Implementierung python import re Komplexer regulärer Ausdruck pattern Za def validate password password return re match pattern password is not None Theoretische Grenzen Chomsky Hierarchie Reguläre Ausdrücke entsprechen Typ Grammatiken in der Chomsky Hierarchie Beschränkt in ihrer Ausdruckskraft Können keine verschachtelten Strukturen oder Rekursionen darstellen Performancebetrachtungen Regex Typ Matching Effizienz Speicherkomplexität Einfache Muster Komplexe Muster Backtracking Regex Exponentiell Hoch Praktische Anwendungsfelder Textsuchoperationen Validierung von Eingabedaten Parsen und Transformieren von Zeichenketten Compiler Entwicklung Netzwerk Protokoll Parsing Konzeptionelle Warnung Obwohl extrem mächtig können überkomplexe reguläre Ausdrücke
set1 = example_chat.body["ngram"][1]
set2 = example_chat_2.body["ngram"][1]
jaccard_similarity = round( len( set1.intersection(set2) ) / len( set1.union(set2) ) , 2)
print(f"{len(set1)=}, {len(set2)=}, {jaccard_similarity=}")
len(set1)=838, len(set2)=798, jaccard_similarity=0.54