WEMI digital (Präsentation)#
Über diese Seite: Seit bald 15 Jahren verwende ich für Präsentationen keine Slides mehr. Statt dessen erhalten die Zuhörer*innen als digitales Handout eine online verfügbare Singlepage-Webseite. Diese bildet auch die Grundlage der folgenden Präsentation zum Aufsatz “WEMI digital”.
Der Aufsatz:
Vollständges Referenz: Busse, Johannes (2025): WEMI digital. AKWI 2025. DOI: 10.18420/AKWI2025_01. Bonn: Gesellschaft für Informatik e.V.. PISSN: 2944-7682. pp. 19-30. Full Paper. Kiel, Germany. 09.-11.09.2025
Tagungsband online: https://dl.gi.de/handle/20.500.12116/47058
Aufsatz online: https://dl.gi.de/items/0ae8c4c6-ad37-4e6e-b779-56794e09dcc2 > AKWI2025_fullpaper_3.pdf (173.88 KB)
DOI: 10.18420/AKWI2025_01
Preprint Juni 2026:
WEMI-digital_2025-06-20.pdf
Metadatenhaltung und digitale Souveränität#
Mein Forschungsthema: Metadatenhaltung für digitale Artefakte, insbesondere im Umfeld von Linked Open Government Data. Mein Zugang ist vorwiegend ein technischer, ich würde mich als Experte für RDF(S) und Ontologien bezeichnen.
Bezug von Metadatenhaltung zum Thema “digitale Souveränität” unserer Konferenz:
Welche fachlichen Kompetenzen (“Können”) und
welche normativen Kompetenzen (“Dürfen”, auch Verantwortung)
sollen wir in Bezug auf die Metadatenhaltung von Linked Open Government Data (LOGD) bei wem allozieren?
Ausgangspunkt ist die zentrale Fragestellung eines individuellen Akteurs:
Wie behalten wir die Kontrolle, vor allem aber auch die Definitionsmacht über unsere Daten bei uns?
Der Zielpunkt der Argumentation fragt:
Mit welchen Gründen sollten wir einer Vielzahl individueller Kleinakteure die Definitionsmacht über “ihre” Daten entziehen und an (welche?) professionellere Akteure übegeben?
DCAT#
Z.B. “Parkhausbelegung”. Wir suchen bei Govdata.de nach “Parkhausbelegung” und erhalten als Ergebnis 8 Treffer:
Was ist ein Datensatz? Maßgeblich ist https://www.dcat-ap.de/def/dcatde/3.0/spec/:
Enthält Erklärtext auf DE,
ein (etwas unübersichtliches) UML-Diagramm: https://www.dcat-ap.de/def/dcatde/3.0/spec/#diagramm
eine RDF-Repräsentation: https://www.w3.org/TR/vocab-dcat-3/#RDF-representation (nur DCAT 3, nicht DCAT 3 AP de)
Das UML Klassendiagramm ist besser lesbar im übergeordneten internationalen DCAT 3 Standard:

Fig. 1 Quelle: https://www.w3.org/TR/vocab-dcat-3/#dcat-scope, Lizenz: https://www.w3.org/copyright/software-license-2023/#
Die reine DCAT-Klassenhierarchie als Text:
dcat:Resource
ISA
dcat:Dataset
ISA
dcat:Catalog
dcat:DatasetSeries
dcat:DataService
dcat:Distribution
dcat:CatalogRecord
dcat:Realationship
Vorteil von DCAT: volle Souveränität über Datenschema bei der Kommune und dem Fachverfahren (resp. faktisch beim Hersteller der Software)
LRM / RDA#
So sieht aktuell WEMI in LRM aus:
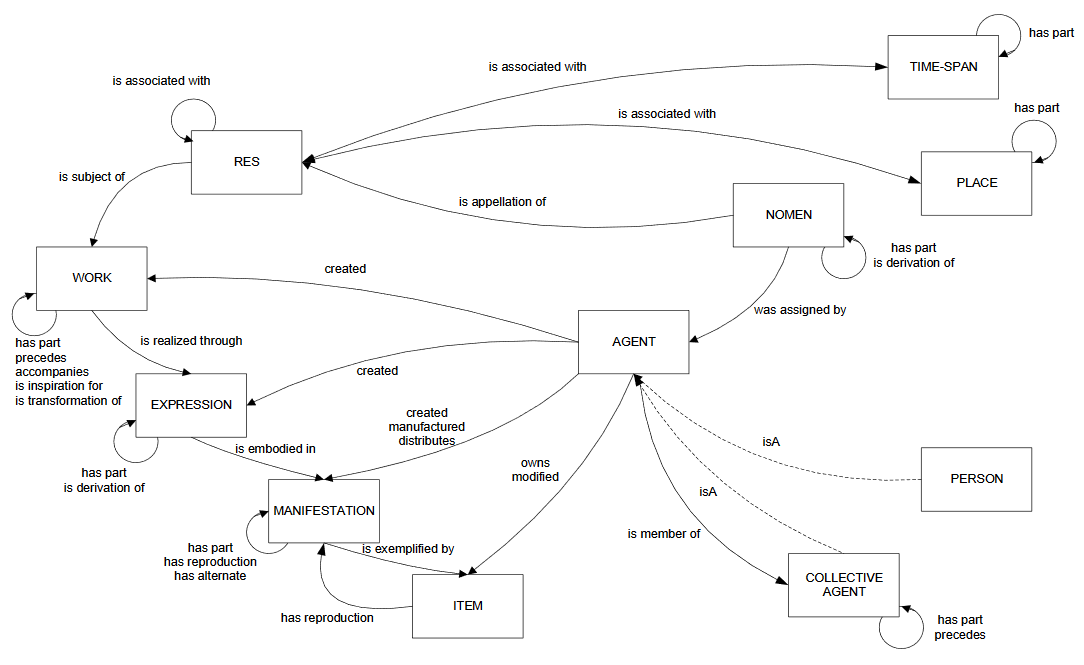
Fig. 2 Quelle: https://en.wikipedia.org/wiki/IFLA_Library_Reference_Model#
Nachteil von LRM: erfordert Bibliothek-Profis bei der Erfassung; nicht leistbar von einer Kommune
Begriff “Datensatz”#
Konzeptuelles Problem: Wollen wir “Datensatz” und “Dokument” miteinander identifizieren? Was ist ein Datensatz? Es kommt etwas auf das Format und das Datenmodell an. Beispiele:
Excel: eine Zeile in einer NFNF Tabelle
ML: eine einzelne Tabelle; eine Spalte in einer Tabelle
Pascal, C, Paython: ein Record, Struct, Dataclass
RDMS: Menge von Zeilen verschiedener Tabellen, die über Fremdschlüssel in funktionaler Abhängigkeit stehen
RDF: ein RDF Graph; ein RDF Dataset (eine Menge von RDF Graphen) … Problem: wie grenzt man “innen” und “außen” eines RDF Graph ab, wenn man das nicht über eine Datei tun will? …
SPARQL: ein Ergebnis einer SPARQL-Query (mithin ein Graph)?
das httpRange-14 Problem#
Zum Beispiel https://musescore.com/mirabilos/hensel-abendlich-schon-rauscht-der-wald:
Fig. 3 Quelle: https://musescore.com/mirabilos/hensel-abendlich-schon-rauscht-der-wald; Lizenz Notensatz: http://www.mirbsd.org/MirOS-Licence.htm, Lizenz Werk: Public Domain#
Wer ist der Urheber?
(a) die Komponistin Fanny Hensel (Schwester von Felix Mendelssohn)?
(b) der Musescore-User mirabilos?
Es kommt darauf an, ob die gegebene URI (a) das Werk bezeichnet, oder (b) die Datei, die auf eine http-Anfrage zurückgeliefert wird.
These: Die Differenzierungen in FRBR WEMI hätten die httpRange-14 Diskussion m.E. stark vereinfachen können.
Kannte Tim Berners-Lee (TBL) dieses Modell? Eine Suche in TBLs persönlichem Blog https://www.w3.org/DesignIssues/ ergibt <site:https://www.w3.org/DesignIssues/ work expression manifestation> 0 Treffer.
Philosophische Bezugsdisziplin: Semiotik#
“Das” semiotische Dreieck :
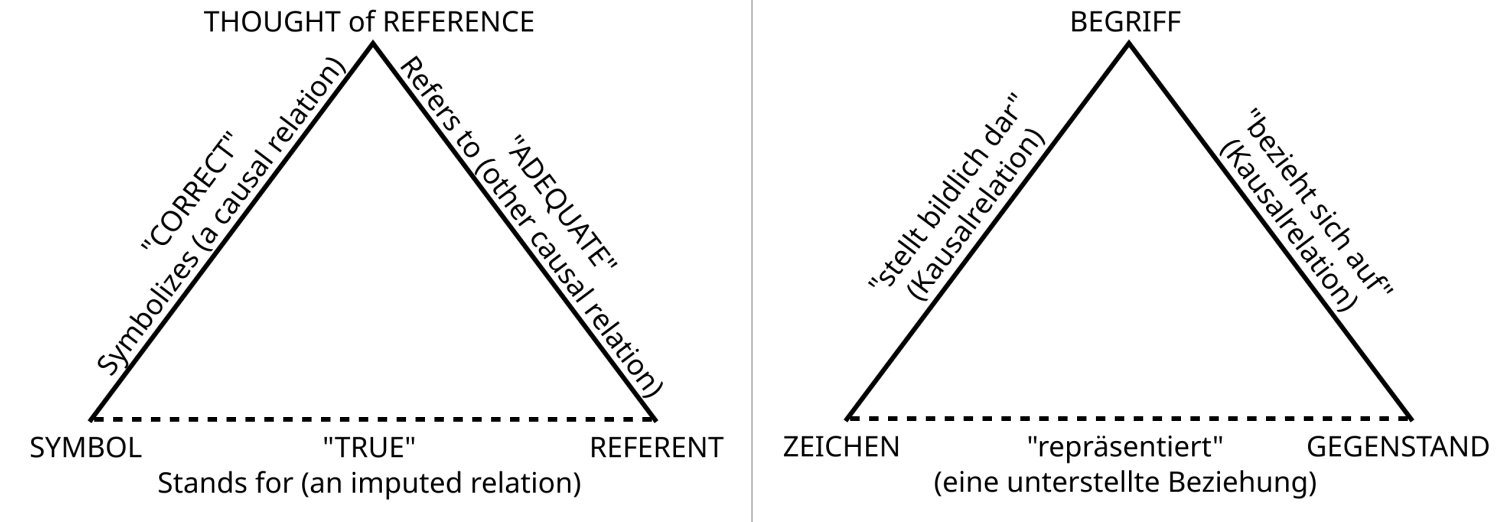
Fig. 4 Quelle: https://commons.wikimedia.org/wiki/File:Ogden_semiotic_triangle.svg#
{kind=link}
Wir haben es mit Grundfragen der philosophischen Ontologie zu tun. Philosophische Kernbegriffe:
denotieren, identifizieren, beschreiben, repräsentieren, bedeuten etc.
Zeichen, Symbol, Indentifier, Begriff, Gegenstand etc.
RDF 1.2#
https://www.w3.org/TR/rdf12-concepts/#resources-and-statements
Any IRI or literal denotes something in the world (the “universe of discourse”). These things are called resources. Anything can be a resource, including physical things, documents, abstract concepts, numbers and strings; the term is synonymous with “entity” as it is used in RDF 1.2 Semantics [RDF12-SEMANTICS]. The resource denoted by an IRI is called its referent, …
Problem: Das Dokument erklärt die Grundbegriffe von RDF rein normalsprachlich. Meines Wissens nach verfügen die Autoren über keine formale Spezifikation zu den Grundbegriffen der Spec wie inbesondere denote u.a. Der Begriff denotieren wird in der Spec der formalen Semantik auf die mathematische Modelltheorie zurückgeführt:
https://www.w3.org/TR/rdf12-semantics/#notation
The word denotes is used here for the relationship between a ground RDF term and what it refers to in a given interpretation, itself called the referent. (The phrase refer to is often used instead of denote and denotation instead of referent.) IRI meanings may also be determined by other constraints external to the RDF semantics; when we wish to refer to such an externally defined naming relationship, we will use the word identify and its cognates.
Die RDF Spec differenziert zwar zwischen abstraktem Graph und konkretem Graph (Serialisierung), ist aber in Bezug auf Dateien / Dokumente nicht ganz klar:
https://www.w3.org/TR/rdf12-concepts/#change-over-time
We informally use the term RDF source to refer to a persistent yet mutable source or container of RDF graphs. An RDF source is a resource that may be said to have a state that can change over time. A snapshot of the state can be expressed as an RDF graph. For example, any web document that has an RDF-bearing representation may be considered an RDF source.
Intuitively speaking, changes in the universe of discourse can be reflected in the following ways: […]
RDF sources may change their state over time. That is, they may provide different RDF graphs at different times.
Some RDF sources may, however, be immutable snapshots of another RDF source, archiving its state at some point in time.
Vermutung: Man kann FRBR (und LRM) WEMI so zu einem WEMI digital erweitern, dass insbesondere auch RDF Graphen, RDF Datasets, RDF sources, RDF snapshots etc. mit dem WEMI-Modell sauber durch Metadaten verzeichnet werden können.
Anwendung: Parkhaus-Daten#
Datenbank 1: Stammdaten: Parkhaus-ID, Ort, Eigenschaften
Datenbank 2: Parkhaus-Belegungsdaten: Parkhaus-ID, Zeitstempel, frei, belegt
Uns interessieren im folgenden nur die Belegungsdaten.
Idee: Ein einziger Datensatz besteht aus
einem Datenschema; im Semantic Web die Terminologie, die T-Box
sowie allen (!) Zeilen / Records / Teilgraphen, die diesem Schema gehorchen; im Semantic Web die sog. Assertions, die A-Box
Das Werk ist dieser eine (!) Datensatz als Idee. Das Werk wird durch zwei Expressionen (partiell, nichtkonkurrierend, komplementär) zum Ausdruck gebracht:
T-Box (das Schema)
A-Box (die eigentlichen Daten)
Die wemi:Expression für das Datenschema besteht aus einer Anzahl von Teil-Expressionen (mit zugeordneten Manifestationen), z.B. https://docs.datex2.eu/v3.2/downloads/parkinglight.html:
EN Text
UML-Diagramm
XSD-Schema
idealwerweise auch RDF(S) oder OWL T-Box
etc.
Die wemi:Expression für die A-Box ist der abstrakte Graph, der über alle Parkhaus-Belegungen der Erde über alle Zeiten Auskunft gibt und mit dem Schema kompatibel ist.
Dieser eine Graph ist selbstverständlich zu umfangreich, um jemals vollständig in einer einzelnen Manifestation (Datenbank, Datei) vorgehalten werden zu können. Faktisch liegen die Daten aber in tausenden einzelnen Dateien und Datenbanken (wemi:Manifestationen) auf den Festplatten der Parkhausbetreiber vor. In DCAT werden diese einzelnen wemi:Manifestationen dcat:Distribution genannt. Im WEMI-Modell wären das Teil-Manifestationen einer einzigen Expression.
Wie sieht das derzeit auf Govdata.de mit DCAT aus?
ergibt (Stand 2025-09-03) 8 Treffer
Zusammenfassung#
“volle Souveränität der Kommune” ist m.E. ein großer Nachteil – das können wir nicht wollen
Erfassung, Verschlagwortung von Datensätzen erfordert Profis. Wir benötigen für die Sicherstellung von Datenqualität, Provenienz, Auffindbarkeit etc. professionelle Akteure
LRM / RDA WEMI kann das bei geeigneten Erweiterungen gut leisten; erforderlich ist eine engere Zusammenarbeit zwischen LOD- und Bibliothkesexperten.
Kurz: Wenn schon Buchtitel nicht durch die Autoren, sondern durch Verlage oder die Deutsche Nationalbibliothek professionell erfasst werden: Warum sollte das nicht auch für die abzählbar wenigen Datenexport-Schemata erfolgen, die in den aufwändig eingekauften und konfigurierten Fachverfahren deutscher Verwaltungen zur Verwendung kommen?